|
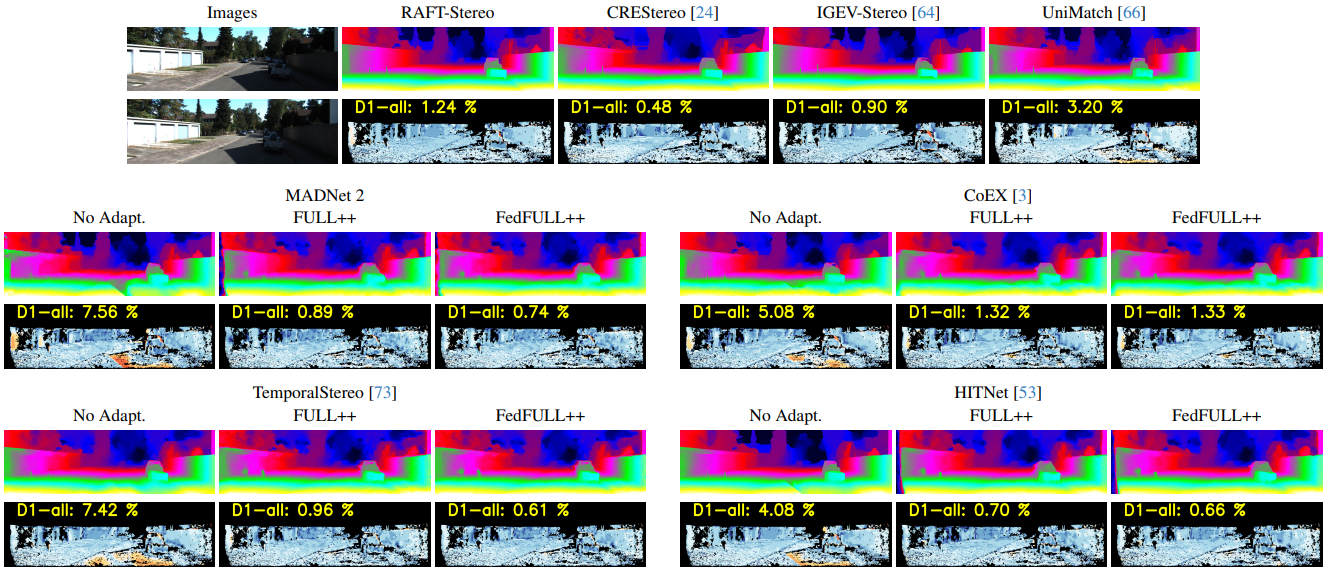
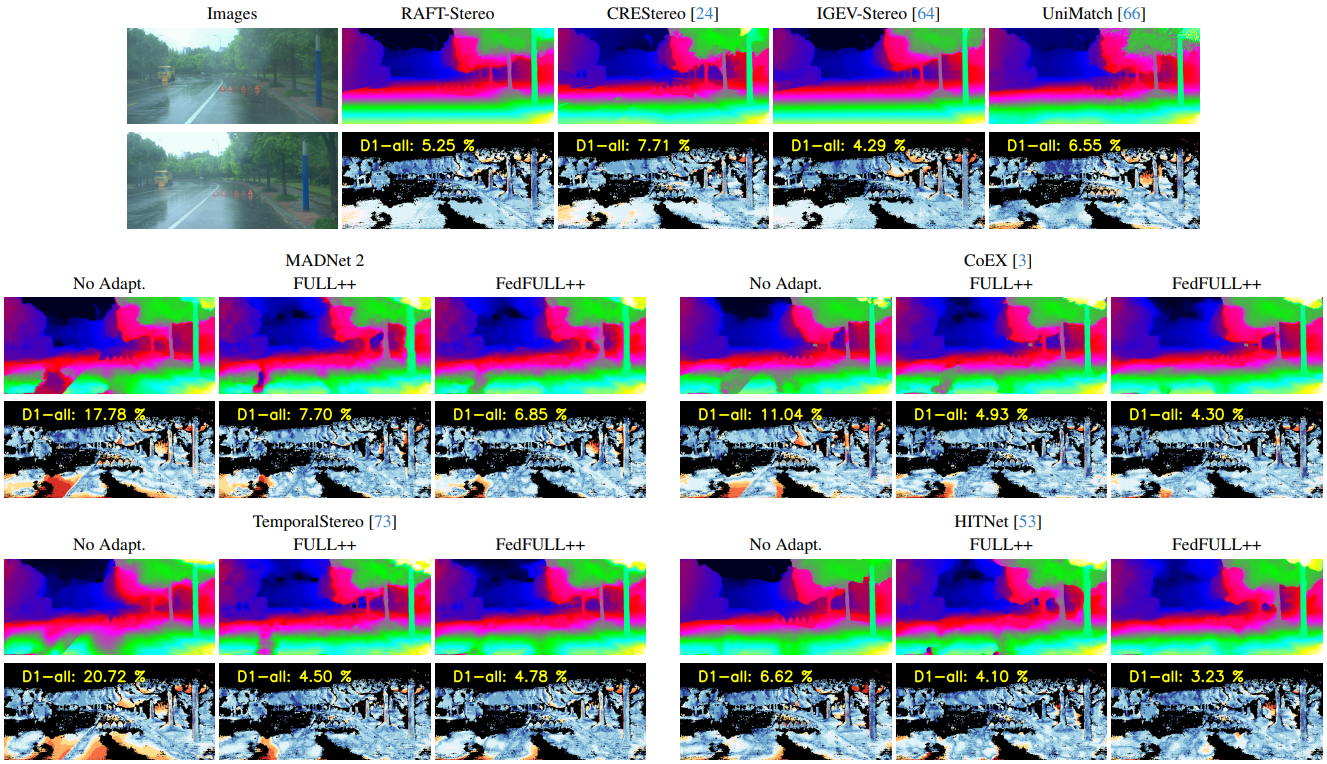
Federated adaptation in challenging environments. When facing a domain very different from those observed at training -- e.g., nighttime images (a) -- stereo models suffer drops in accuracy (b). By enabling online adaptation (c) the network can improve its predictions, at the expense of decimating the framerate. In our federated framework, the model can demand the adaptation process to the cloud, to enjoy its benefits while maintaining the original processing speed (d). |